
ホームページデータのバックアップは保存していますか?
何らかのトラブルでサーバー上のデータが消えてしまった。
手もとにもバックアップデータが無い!Oneドライブにも無い。
そんな状況になった場合に役立つお話です。
まだあなたにはInternet Archivesが残ってる!
当店で扱う本も、ホームページの記事も全て大事な情報です。諦めて1から構築しなおすのも手ですが、沢山の時間(お金も?)を費やて作ったものを手放してしまうのも悔しい事ですよね。
諦めるのはまだ早い!あなたのデータを取り戻せるかもしれません。
Google等の検索エンジンがインターネットを巡回して記事を読み込み検索エンジンに登録していることは皆さんご存じだと思います。機械がだからこそできる何億とあるサイトの情報収集作業。Googleは主に記事に関してこの作業を行っているわけですが、インターネット上で公開されているホームページそのものを、「そのままの形で」保存している組織があるのをご存じでしょうか?有名なものの1つがアメリカの非営利団体が運営するInternet Archivesです。
このページの目次
Internet Archivesにデータが残っているかも
ウェイバックマシン(Wayback Machine)
1996年から収集開始されておりインターネット上のホームページデータを自動収集し同組織のサーバーに補完しています。著作的には米国著作権法のフェアユース規定にもとづいてウェブアーカイブを構築しているようです。
【ここで、ひそひそ話】
Internet Archivesは書籍に関するアーカイブ化も行っていて、このあたりは本屋から見ると、えーそれってちょっとどうなの?という点でもあります(過去にパソコン系の古い雑誌についてネットで話題になってたことがありました)。
「ひそひそ話」で気になるのは「著作権」ですよね。今回は「サーバートラブルなどで失った自分のホームページのデータ」、つまり自分自身に権利があるコンテンツを回復させるために使用していきます。
といってもそんなに複雑な話ではありません。
以下のURLにアクセスし、トップページにあるWAYBACKMACHINEの入力欄に表示したいドメイン(例:www.yourdomain.com)で検索してみてください。
Internet Archivesでホームページデータが保存されいるかを調べる
以下のURLにアクセスし、トップページにあるWAYBACKMACHINEの入力欄に表示したいドメイン(例:www.yourdomain.com)で検索してみてください。

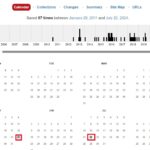
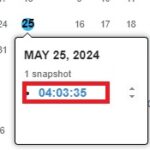
日付を選んで表示してみる
Internet Archivesによりホームページが取得さていれば、カレンダーのような画面が表示されます。その画面の日時をクリックすることで、その時点でのホームページデータが表示されるのです。
一般ページも保存されている可能性が高い!
リンクを正しくたどることが出来るように設計されていれば、トップページだけでなく一般ページの記事や画像も保存されている可能性が高いです。このあたりはGoogleと同じだと思います。ページ内リンクを正しく構築しているこが大事なわけですね。
復旧に必要なページのコードと画像をコピーする
さあコンテンツがあるのは分かりました。ホームページを復活させるために必要なページをコピーして保存していきましょう。
だけど、コピーするだけでいいの?と疑問に思ったあなたは正解です。
表示されているホームページのコードを見てみればわかりますが、Internet Archives内で表示するために必要な箇所を自分で書き換えてますね。ということは、この方式ではページをコピーした後にコードの修正をする必要があるということです。あるいは初めからその部分を切り落とした(スクレ―ビング)した状態で取り込むかということになります。
理屈は分かった、あとは実行あるのみ!
必要な箇所を自分で書き換える道を選んだ人はひたすら、データコピーしてコードを確認しながら、必要な箇所のコード書き換えを繰り返せば完成です。ホームページのコーディングを多少経験している方で対応するのが、数ページであればこのやり方で十分いけるでしょう!
もっと手間を掛けずにやる方法があるのではないか?
そもそもインターネットのホームページデータは一旦オリジナルの形で保存されてるんじゃないのか?と思ったあなたは実にするどいです。そして収集したものをオリジナルの形で一括でダウンロードする方法もあるのでは?と。
あるんです。以下対応方法です。
Internet ArchivesのAPIを使用して自分でプログラムを作ってしまう
Internet ArchivesにはいくつかのAPIがあり、それを使用することで自作プログラムで上記機能を実現できるようです。費用はかからず、必要なのは時間と技術、そして根性!?だけですね。いきなりハードル上げ過ぎましたかね。。
事業者サービスを利用する
Internet Archivesの以下のページで紹介されています。いずれも対応は英語となるようですが、FAQの1つとして掲載されてます。ただ英語で書かれた外国語サービスを利用することに抵抗があるという人も多いかと思います。かくいう私もその一人です。
https://help.archive.org/help/can-i-rebuild-my-website-using-the-wayback-machine/
GitHUBのプログラムを使用する
1に近いと思いますが、あるんです。ダウロード用プログラム。Rubyで開発されており、いくつかフォーク(枝分かれ)して改良が続けれらています。
ダウンローダの例
https://github.com/hartator/wayback-machine-downloader
【重要:手順通りに使えば正常に動くとは限りません】
当店でも上記URLのダウンローダを利用としてみましたがエラーが出てダメでした。2024年12月現在、動くものとそうでないものがあるようで、オープンソースものにありがちですが、今動くものも、いつまでも正常に動くとは限りません。そんな中見つけたのが下記の記事。
https://github.com/hartator/wayback-machine-downloader/issues/307
記事(英語)の通りに試してみると、見事!!動きましたね!Internet Archivesから必要なサイトのホームページデータをダウンロード出来ました!
ということで、あるサイトのレスキューをお客さんから相談されていたのですが、これでデータを取り出すことが出来ました。とあるサイトは2024年12月で運用が一方的に止まったCsideNetのサーバーに収容されていたのです。ネットで検索してみるとこのサーバー、いわくつきですね。
その後、ローカルのテスト用WEBサーバー(RockyLinuxのapache)に展開し問題なく動作することを確認しました。gitHUBスバラシイ。
お客様にも確認してもらった後、本番機サーバーに展開する予定です。
あ、今回はドメイン変更するので、もうひと手間、手作業での文字置換が必要になりますね。
自分では無理?当店がお力になれるかもしれません
上記手順を読んでも自分で無理、何がなんだかわかんない!自分にはそんな複雑な作業は無理だから~という方へ。当店がお力になれるかもしれません。
まずはお問い合わせフォームよりご相談下さい。
お問い合わせ内容は「その他お問い合わせ」を選択。内容欄には以下の内容をご記入下さい。
※※※※※※必要事項※※※※※※※※
ホームページデータのご相談
URL:
お名前:
ホームページとお客様のご関係:
お困りごとの内容:
※※※※※※※※※※※※※※※※※※
【注意事項】
・相談は無料ですが、その範囲は当店の規定に準じます。
・対応が有料となる場合は、必ず事前にお見積りを行います。
・内容および当店の状況によってご相談をお断りする場合があります。
・こちらのサービスはお電話での対応は行っておりませんのでご了承下さい。